Spezifikation
1. Aufgabenzusammmenfassung
Grundlage dieser Aufgabe ist eine physikalische Problemstellung, die Berechnung der Kapazitätswerte von Zylinderkondensatoren.
Der Aufbau eines solchen Kondensators kann aus unten dargestelltem Bild entnommen werden.
Die Kapazität eines Zylinderkondensators ist im Allgemeinen abhängig von der Länge l des Kondensators, den Radien
des inneren und des äußeren Zylindermantels (r1 und r2) sowie dem verwendeten Isolatormaterial, Dielektrikum genannt.
Zur Repräsentation der Einflüsse, welche die Wahl des Dielekrikums auf die Kapazität hat, wurde eine materialabhängige Konstante,
εr, die relative Dielektrizitätszahl
eingeführt.
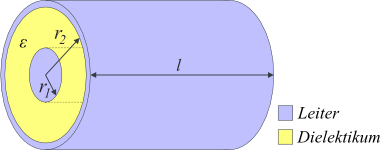
Sind diese 4 Parameter (Länge, Dielektrizitätszahl, innerer & äußerer Radius) gegeben, so lässt sich die Kapazität des entsprechenden Kondensators mittels folgender Formel errechnen:
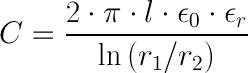 Hierbei bezeichnet
Hierbei bezeichnet ε0 die elektrische Feldkonstante, die Dieelektrizitätszahl des Vakuums (8,8541878*10^-12 As/Vm).
Um die einfache Berechnung großer Mengen an Kapazitätswerten zu ermöglichen, soll im Laufe des ETI-Praktikum ein Programm konzipiert, implementiert und getestet werden, welches die Auswertung dieser Formel automatisiert. Die Länge des Kondensators sowie die beiden Radien werden von dem Programm aus einer Datei eingelesen, wohingegen die relative Dielektrizitätszahl fest im Programm verankert werden sollen: Für jedes Tripel an Größeninformationen sollen die Kapazitäten der entsprechenden Kondensatoren jeweils mit Paraffin und Ölpapier als Dielektrikum errechnet werden.
Als Grundgerüst für dieses Programm steht die Datei read.c zur Verfügung, welche einige Werte aus einer Datei ausliest, in Arrays speichert und dann
eine noch nicht implementierte calc-Funktion mit Pointern auf diese Arrays als Parameter aufruft. Primäres Ziel ist eine Implementierung der calc-Funktion,
welche die eigentliche Berechnung der Kapazitätswerte durchführt. Um diese calc-Funktion dem Benutzer bequem zugänglich zu machen, ist des Weiteren eine
Anpassung des Rahmenprogramms notwendig, da dieses z.B. von einer ungeeigneten Funktionssignatur der calc-Funktion ausgeht. Das Rahmenprogramm darf hierbei
in C geschrieben werden, die calc-Funktion muss jedoch zwingend in x86-Assembler geschrieben werden, ohne die Verwendung von Befehlssatzerweiterungen wie
beispielsweise MMX oder SSE2.
2. Voranmerkungen
Bevor auf die eigentlichen erarbeiteten Lösungsansätze genauer eingegangen werden kann, müssen noch von der zentralen Aufgabe unabhängige Aspekte betrachtet und erläutert werden. Im Zentrum dieser Aufgabe steht die Berechnung von Kondensatorkapazitäten mithilfe von einer in Assembler (NASM-Syntax) implementierten Prozedur, die aus einem C-Programm heraus aufgerufen wird. Die Werte, die zur Berechnung verwendet werden, sollen in einer speziellen Datei abgespeichert werden. Diese wird zur Laufzeit des Programms vor der Berechnung eingelesen. In diesem Sinne ist es also notwendig, auch über die Realisierung des C-Rahmenprogrammes und über die Speicherung der Daten in der vorher erwähnten Datei zu sprechen.
Ein C-Rahmenprogramm war ursprünglich zwar gegeben, ist allerdings aufgrund einiger Fehler unbrauchbar. Wir haben uns deshalb dazu entschlossen, das C-Rahmenprogramm noch einmal selbst, unseren und Ihren Anforderungen genügend, zu implementieren.
Zur Speicherung der Größen, die vom C-Programm eingelesen und zur Berechnung an die Assemblerprozedur übergeben werden, haben wir uns auf die Verwendung des CSV-Formats geeinigt. Vorteil dieses Formats ist neben seiner einfachen Struktur die Tatsache, dass man CSV-Dateien auch bequem mit etablierten Tabellenkalkulationsprogrammen wie z.B. Microsoft Excel oder OpenOffice bearbeiten und verwalten kann.
Eine beispielhafte CSV-Datei soll uns dabei sogleich als Testcase dienen. Selbstverständlich ist auch während der Entwicklung für andere Testcases gesorgt.
Die zu implementierende calc-Function besitzt wie bereits in der Aufgabenzusammenfassung erwähnt die folgende C-Signatur void calc(int* in1, float* in2, float* in3, float* out1, float* out2), für die Formel zur Berechnung von Kondensatorkapazitäten siehe ebenfalls oben.
Die Werte l, r1 und r2 liegen in Arrays, deren Adressen vom C-Rahmenprogramm an die calc-Function übergeben werden. ε0 ist eine Konstante, εr ist unterschiedlich für Paraffin und Ölpapier. Um die Berechnung möglichst schnell und effizient zu realisieren bietet es sich an, konstante Teilausdrücke zusammenzufassen und als konstanten Faktor im Programm zu verankern. Hierbei gibt es zwei Möglichkeiten: Entweder wird das Produkt von 2*π*ε0 fest im Programm verankert, dieses dient dann wieder als Faktor für den Rest der Formel. Damit ist die Formel nach wie vor universell, und die Werte für εr, die für unterschiedliche Temperaturen unterschiedliche Werte annehmen können, könnten auch vom Benutzer manuell spezifiziert werden. Um Fehleingaben entgegenzukommen würden auch Defaultwerte für epsilon_r im Programm hinterlegt. Die zweite Möglichkeit besteht darin, die Werte von 2*π*ε0*εparaffin und 2*π*ε0*εölpapier fest im Programm zu verankern. Das Programm ist dadurch schneller, da eine Multiplikation eliminiert wird, andererseits verliert es an Dynamik, da \epsilon_r nicht mehr selbst angegeben werden kann. Aus Gründen der Flexibilität haben wir uns für erstere Lösung entschieden.
Wir werden die Signatur der besagten calc-Function also noch um ein paar Parameter erweitern, und zwar Folgende: zwei nicht obligatorische Floats εr1 und εr2 von Paraffin und Öl, und ein Parameter der angibt, wieviele Datensätze überhaupt berechnet werden sollen. Das erhöht die Flexibilität des Programms noch einmal, denn man kann dann letztendlich unbegrenzt viele Werte in die CSV-Datei eintragen und berechnen lassen.
Den eigentlichen Schwerpunkt stellt aber die Berechnung des Logarithmus im Nenner der Formel dar. Diese wird im Folgenden in unseren beiden Lösungsansätzen genauer betrachtet.
3. Lösungsansätze
3. a) Lösungsansatz 1
Der Term im Nenner der zu implementierenden Formel, also ln(r1/r2) lässt sich gemäß den logarithmischen Gesetzen umformen zu ln(r1) - ln(r2). Das mag mathematisch zwar äquivalent sein, kann in Assembler verschieden implementiert werden. Im Vordergrund steht dabei die Frage, welche der beiden Schreibweisen schneller und effizienter implementiert werden kann.
In unserem ersten Lösungsansatz wählen wir den Term in der Form ln(r1/r2), was bedeutet, dass in Assembler r1 zuerst durch r2 geteilt werden muss, und anschließend darauf der Logarithmus angewendet werden kann.
3. b) Lösungsansatz 2
In unserem zweiten Lösungsansatz liegt der Nenner in der Form ln(r1) - ln(r2) vor, der natürliche Logarithmus muss also zweimal berechnet werden, allerdings wird dadurch die die Division von r1 durch r2 eliminiert. Dieser Lösungsansatz bietet nun auch die Möglichkeit, die Berechnung beider Logarithmen auf einem Multicore-Prozessor zu parallelisieren (echte Parallelisierung ist nur auf einem Multicore-Prozessor möglich, da der zu verwendende Befehl nur auf der FPU ausgeführt werden kann. Auf der CPU funktioniert dies höchstens mithilfe einer speziellen Näherungsformel, welche aber wieder einen Effizienzverlust zur Folge hätte).
4. Diskussion der Lösungsansätze
Bewertungskriterien für die Abwägung zwischen den beiden Lösungsansätzen sind Komplexität der Implementierung, Geschwindigkeit der Ausführung und Kompatibilität. Im Bezug auf die Ausführungsgeschwindigkeit stellt sich die Frage, ob die Berechnung einer Division schneller oder langsamer als die Berechnung des natürlichen Logarithmus ist. Schließlich muss im Lösungsansatz 1 eine Division und eine Logarithmusberechnung durchgeführt werden, wohingegen beim Lösungsansatz 2 eine Subtraktion und zwei Logarithmusberechnungen stattfinden. Einfacher zu implementieren ist mit Sicherheit eine Division mit anschließender Logarithmusberechnung. Unsere Recherchen haben ergeben, dass die Berechnung des Logarithmus zur Basis 2 auf der FPU unvergleichbar mehr Taktzyklen in Anspruch nimmt als eine Division durch einen beliebigen Wert auf der FPU. Rechenzeit ist jedoch kostbar, deswegen implementieren wir unseren Lösungsansatz 1.
5. Abschlussbemerkungen
Zur Berechnung des natürlichen Logarithmus werden wir, insofern es damit nicht zu Konflikten kommt, die FPU-Befehle FYL2X := y*log2(x) und FLDLN2 (lädt den natürlichen Logarithmus von 2) verwenden. Um damit den in der zu implementierenden Formel benötigten natürlichen Logarithmus zu erhalten bedienen wir uns eines kleinen Kniffes: Für die Basisumrechnung vom Logarithmus zur Basis 2 zum natürlichen Logarithmus gilt gemäß den Basisumrechnungsgesetzen ln(x) = log2(x)/log2(e) = log2(x) * 1/log2(e) = log2(x) * log2(2)/log2(e) = log2(x) * ln(2). Es genügt also zur Umrechnung den Logarithmus zur Basis 2 eines Wertes mit der Konstanten mit dem Wert ln(2) zu multiplizieren. Den Wert von ln(2) liefert uns dabei der Befehl FLDLN2. Mithilfe von FYL2X ist es dann ein Leichtes, den natürlichen Logarithmus zu berechnen.
Desweiteren stand die Diskussion im Raum, ob man denn irgendwelche Berechnungen auf CPU und FPU parallelisieren könnte und sollte. Nach genaueren Betrachtungen haben wir uns gegen eine Parallelisierung entschieden, da damit das Programm nur an Komplexität gewinnen würde, der Effizienzzuwachs aber nur marginal wäre.